
Page 71 - 2018自動化工業總覽
P. 71
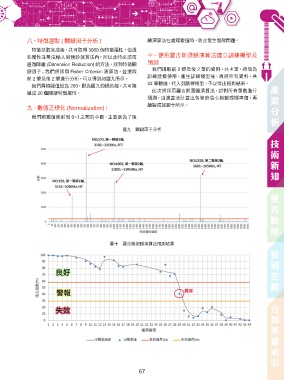
八丶、特徵選取 ( 關鍵因子分析 ) 續演算法在處理數值時,防止發生發散問題。
特徵萃取完成後,共可取得 3060 個特徵屬性,但這
些屬性並無法輸入到預診演算法內,所以此時必須再 十、丶使用羅吉斯迴歸演算法建立訓練模型及
通過降維 (Dimension Reduction) 的方法,找到特徵關 預測
我們提取前 2 群及後 2 筆的資料,共 4 筆,將做為
鍵因子;我們將採用 Fisher Criterion 演算法,並提取
訓練建模使用。產生訓練模型後,再將所有資料,共
前 2 筆及後 2 筆進行分析,可以得到如圖九所示。
33 筆數據,代入到訓練模型,予以得出預測結果。
我們再將閥值設為 200,即為圖九的橘色線,共可降
此次將採用羅吉斯迴歸演算法,針對所有筆數進行
維成 20 個關鍵特徵屬性。
預測,由演算法計算出各筆的信心指數或機率值,再
繪製成如圖十所示。
九丶、數值正規化 (Normalization):
我們將數值映射到 0~1 之間的小數,主要是為了後
圖九 關鍵因子分析
圖十 羅吉斯迴歸演算法預測結果
67